
Lost benefit of unit testing

Unit testing is good. It comes with a lot of advantages, but somehow there are still many people who hate it. That’s why we shouldn’t blame the testing itself, but the way we perform it.
(In the article, I use the words mock/mocking in several places, although test double would be the correct term, but in many cases, it was more convenient)
So let’s look at those advantages:
- Better design — it’s self-evident that to write a unit test for a specific unit, it must be written in a way that it is easily separable from the rest of the code.
- Documentation — the name of the tests itself documents how the given unit works. Even with poorly named test methods, you can figure out what they do by looking inside.
- Debugging — even though they aren’t meant for that, tests help us catch regressions.
- Long-term cost reduction — For projects that last longer than a few weeks and are more complex than a landing page, tests help avoid the chaos that would later cause extra work hours, saving us money.
- Safe refactoring — this is what this article will focus on.
What is refactoring?
Refactoring is the process of restructuring code without changing its external behavior.
What do we mean by “without changing its external behavior”? It means selecting a code segment and changing it such that pre- and post-conditions remain unchanged. The code will perform the same tasks as before. If this specific code segment is a method, it means that the interface doesn’t change, only the internals do.
How do we ensure that nothing has changed? This is where the tests come into play.
If we had tests for that code segment, we simply run them, and any failure indicates that we’ve changed its behavior.
Refactoring vs. New Features
Refactoring is the process where we restructure the code while intentionally NOT modifying the behavior.
Adding a new feature, on the other hand, is when we intentionally modify the behavior.
Most people confuse refactoring with adding new features to the system. This process often doesn’t stop at the class level but involves rewriting heaps of code, making matters even worse. At the end, when running the tests, they break spectacularly. But what’s the cause? Refactoring? Or does the logic added with the new feature somehow not fit into the system? Who knows? As a result, people end up rolling back their changes, or worse, rewriting the tests to fit the new circumstances, even if they don’t understand them.

I wouldn’t recommend either. Simply cobble together the code completely until the feature works — of course covered by tests — and then start tidying up what you’ve done.

During one of my lectures, someone from the audience asked if they were doing something wrong because
A bunch of tests broke when I refactored the code, so I had to adjust them afterward…

When you refactor, you should not be altering the tests, otherwise, you can no longer call it refactoring.This is slightly different from what I was saying earlier, as in this case, it’s allegedly just about refactoring, not mixed with new features.
So what could still be the trouble? The fact mentioned about “a bunch of tests” breaking makes me wonder how these tests are structured. Of course, it could be because they rewrote half the system — meaning the refactor was too large — or simply because they committed atrocities, like writing overly generic tests, but more on that later.
The important thing is that they recognized the problem, which unfortunately often escapes many developers.
So what could be causing all of this?
- Misunderstandings about refactoring
- The concept of the unit to be tested
- Fragile tests
Let’s examine these one by one!
Misunderstandings about Refactoring
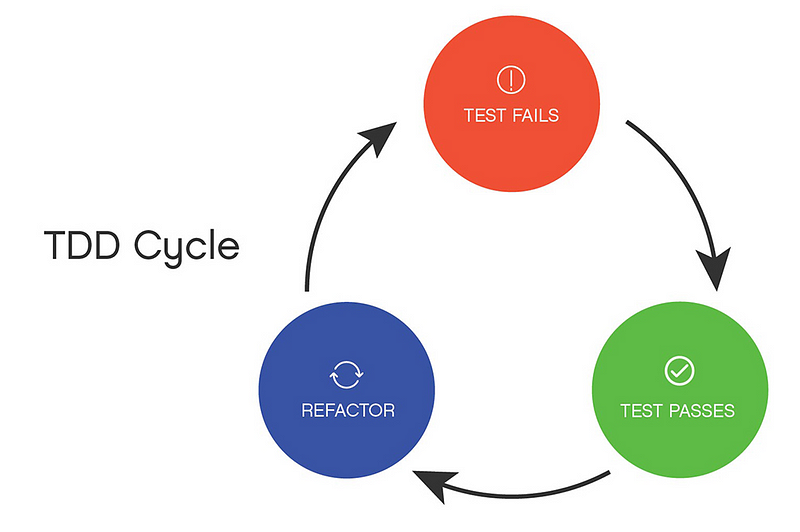
If you look at this image without fully understanding what TDD is, it completely makes sense that tests are expected to break after refactoring.
Although this article is not about TDD at all, let’s look at the diagram above. Why would anyone think that adjusting tests after they’ve broken due to refactoring is bad if such “evidence” circulates the internet? It’s essentially saying that tests will break after refactoring. We’ll fix them and they will be green again. The problem is that the above image excludes the process between each step, unlike the one below:
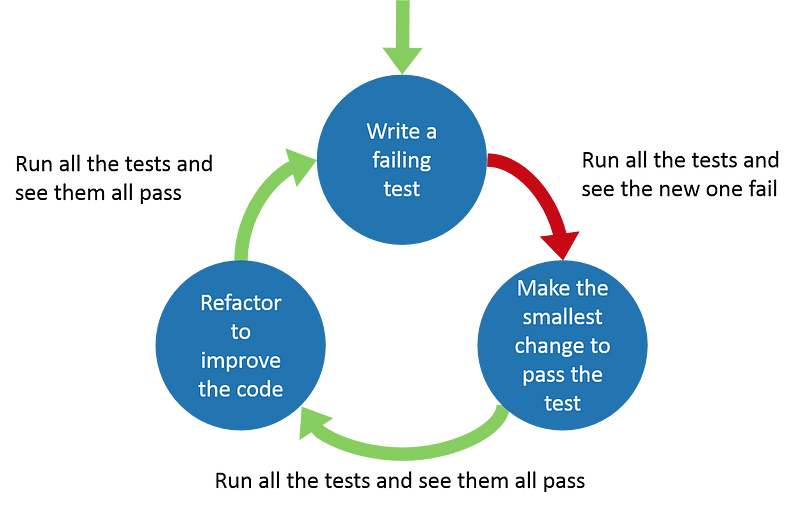
Now this truly tells the truth, suggesting that after refactoring, we are not amidst breaking tests. On the contrary, they should pass successfully for you to proceed.
The Concept of the Unit to be Tested
What is a unit?
Intuitively, one can view a unit as the smallest testable part of an application. — Wikipedia
Intuitively, that’s the word where everything went wrong. If anyone speaks or writes about unit testing, they assuredly mean a method, a class, or sometimes a function.
Everything else gets isolated, and we look inside the small code segment. Of course, when we use static code analyzers like Sonar and the like, we quickly end up with small methods with little complexity, short classes doing only one simple thing. But what does this tiny class with a few lines of code really mean for the business? Does an if-else branch represent a functionality? Let’s see how most developers write tests!
Our Typical Tests

In an OOP environment, usually, we create a test class for each class we intend to test. We run through all the public methods of this class while swapping every collaborator using the available mock framework to focus more on the logic that’s inside.
Let’s assume we have these three classes:
UserServiceEmailValidatorUserRepository
Then we sure can say we also have these three tests:
UserServiceTestEmailValidatorTestUserRepositoryTest
Does this create a problem? No, not until we modify something. Long ago, we learned how important loose coupling is, yet somehow we forgot it in our tests.
With the approach above, we tie the structure of our tests tightly to the live object classes, making refactoring much harder. Although both groups of tests and live objects aim to describe or realize the same behavior, their structures may differ.
I believe — and many may not agree with me — that a class is not the smallest testable unit. In most cases, we already create multiple classes even for the simplest tasks. To me, isolating such class groups gets us to what we can call a unit.

Let’s see an example! We’ll use Java since it’s one of the most prevalent languages. It will be a simple example to be understandable, but complex enough to demonstrate the problem.
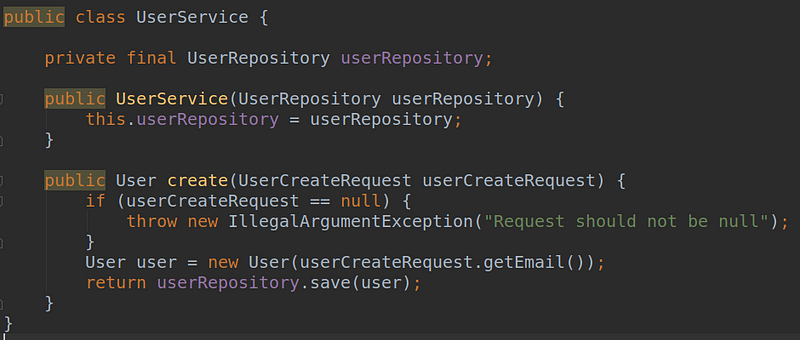
We have a simple service that can create users. There comes a request from somewhere that contains all the information to create it. We perform some basic validation — null checks, to be precise — do some transformation, and already pass it down to lower layers for persistence.
Let’s see how we would structure our test. We’ll start with the earlier one class — one test principle.
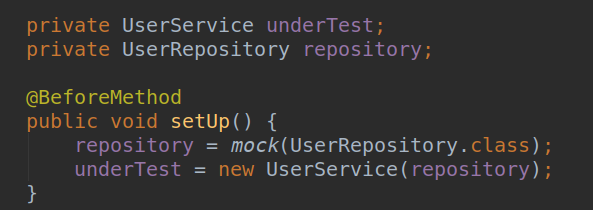
We create a mock for the repository and pass it to the service’s constructor.
Then we create the first tests for it. One for validation, one for transformation, and one to verify we have indeed saved the transformed object.
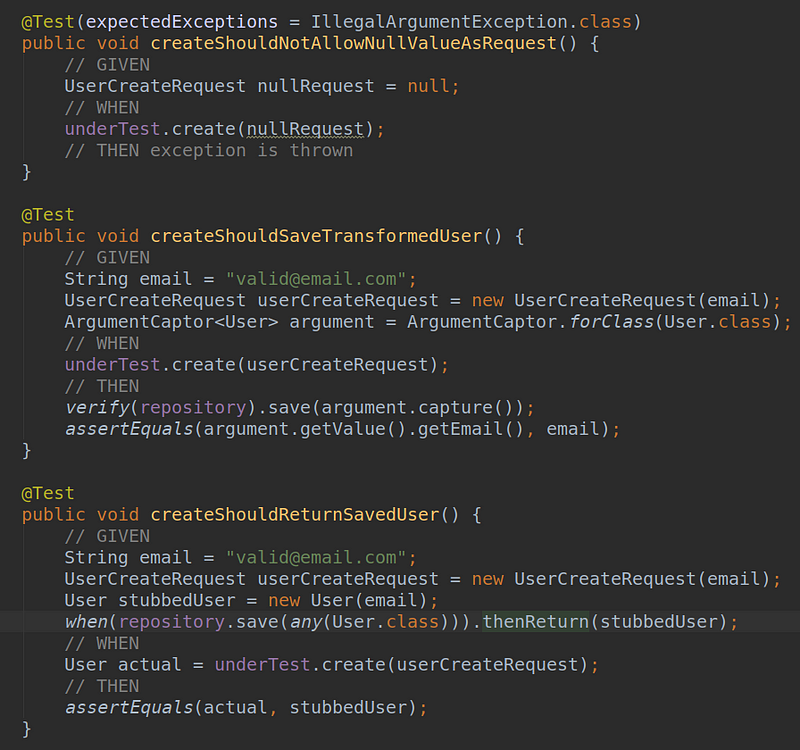
We check the code in small segments. We don’t want to check the entire method repeatedly because the coverage would heavily overlap in that case. If this happens, our tests aren’t specific enough to show precisely where the error lies.
So, we have our tests which we run, and all are green. This is our starting point.
Let’s start refactoring the code. First, we just extract the logic into private methods:
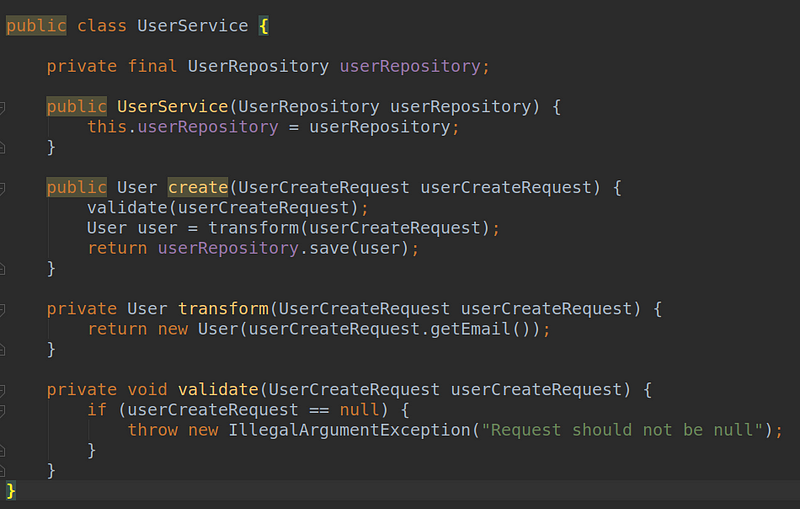
Patience, though these singular methods may seem absurd, the trick applies to major codebases too.
Note: It is clear that private methods are not tested independently but through the public methods.
We modified the live code. We rerun the tests, which are still green, but that’s no big surprise.
Let’s move on with refactoring. How about moving the validator out to a new class?
We create a new class, with a method containing the extracted service code:
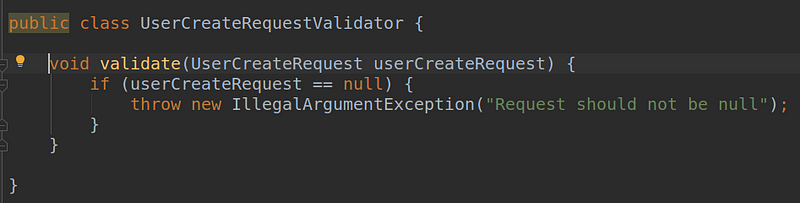
Then we add it to the UserService as a new collaborator and replace the previous private method.
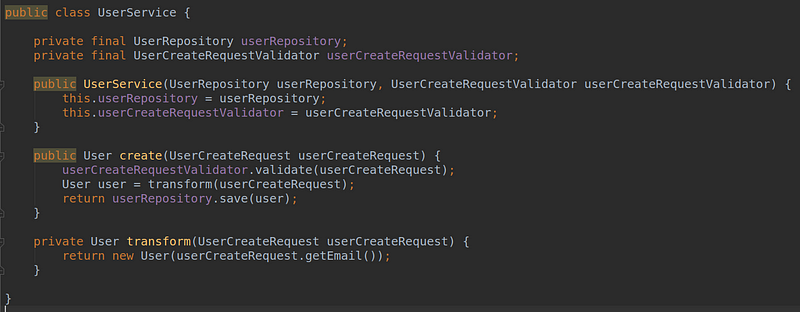
We are finished with refactoring, and even if we don’t follow TDD, our next step is to rerun the tests, expecting them to be green.
But they won’t be.
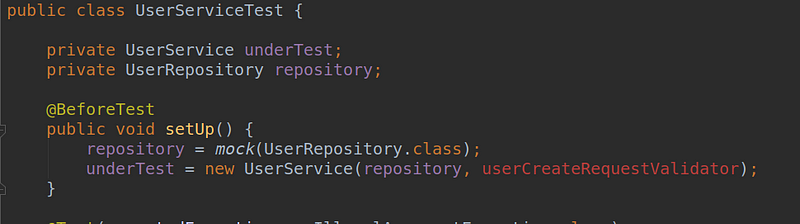
It fails with a compilation error because we added a new constructor parameter that we have not yet defined in the test code. But who cares? Let’s create the corresponding mock and pass it as a parameter:
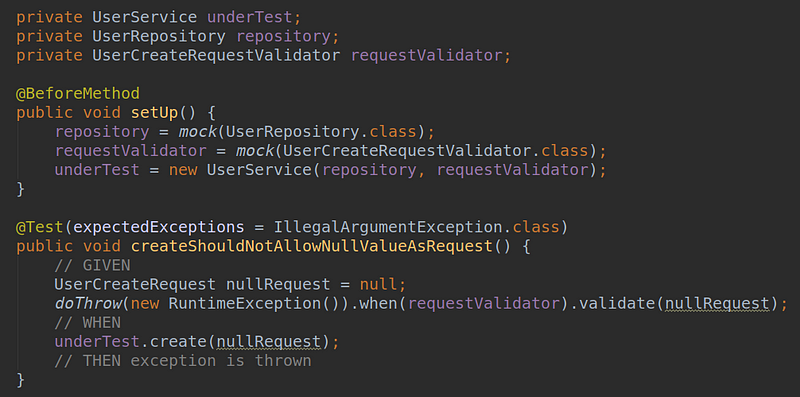
Yes, but simply creating a mock doesn’t solve the problem, because it also needs to be configured, otherwise it won’t throw an exception as expected. Although this seems like a minor adjustment, don’t be fooled; it’s only because our example is small. However, we still had to modify the tests even though the functionality of the create method hasn’t changed at all. And this is the moment when
we lost the security that the tests provided.
But all is not lost, let’s undo our changes and go back to when we broke out the logic into private methods. The tests are green, so we can start refactoring. Our first step is to create a factory for our service:

We create a method named createDefault. The nomenclature is not new at all; many libraries provide default implementations via builders and factories. These allow us to use the library without knowing how the classes are built. Our method can be static since we won’t mock it, there are no elements that make testing difficult such as I/O or threading, and we can use it in the IoC container.
Let’s replace the constructor in the setup method:

This introduced another layer between our test and constructor, eliminating dependencies between interfaces. We don’t see any result yet, but let’s run the tests. They are green.
After that, we just need to repeat our most recent step. Extract the validation logic into a new class—which caused a compilation error last time—and add the instantiation to the factory, which is still production code, right? So we can do it without worry:

Since we are talking about a default implementation, we merely pass a validator. Obviously, we create an overloaded factory method for our IoC container.
If you’re strictly a “mockist,” you might be looking like this right now:

What did I do? Why am I using the actual implementation instead of replacing it with a test double? Because this is part of the test. We moved the logic out of the original class, but are still using it. Instead of creating a new UserCreateRequestValidatorTest class, we do it in our existing test. So if we look at the test coverage, we can see that we covered every branch here as well:
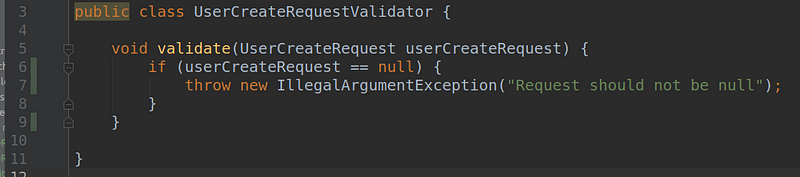
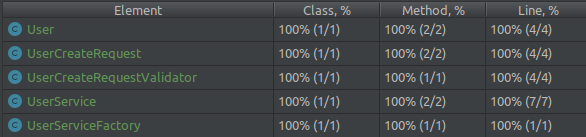
So what did we do? We took a slightly different approach and allowed our tests to cover more area. We let it venture beyond the boundaries of the UserService and reach collaborators as well. Since we are testing broader scope, we can structure our tests differently. So one test will focus on the method of a given class. For other methods, we create new tests, but they still use collaborators.
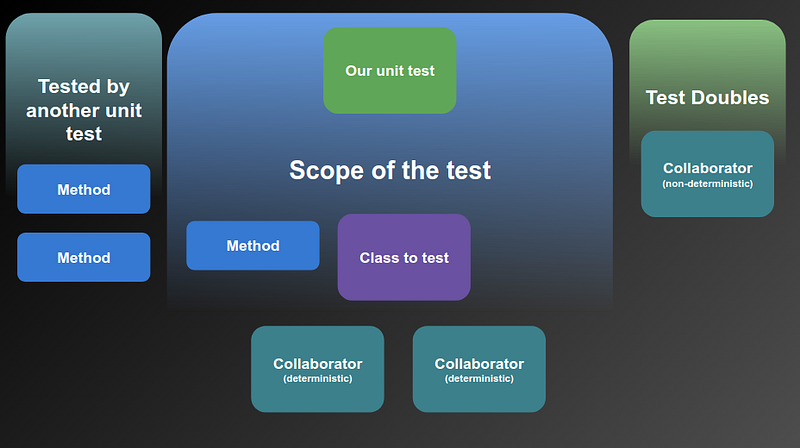
And what kind of collaborators can we use here? Those whose output is deterministic. Pure functions that always produce the same output for a given input. When you pass a null parameter to our validator, it will throw an exception, come hell or high water. These are like functions in a Math library. Call Math.floor(5.1), there’s no chance it returns anything other than 5.
But we still need test doubles in scenarios where the output is non-deterministic, such as with repositories.
Let’s continue refactoring!
We move out the transformer:

Refactor UserService to use it:

And add it to the factory:

Rerun the tests: they are still green.
What about those classes that we use across multiple units? Do we test them again and again with the same cases? Indeed. However, these cases occur in different contexts, therefore when you refactor such a collaborator that’s used in two tested units and the tests for one break, you know you made a modification that doesn’t fit that context.
A Note on Mocking
What would happen differently if we used mocks instead of actual implementations? Let’s go back to the point when we used a mock validator:
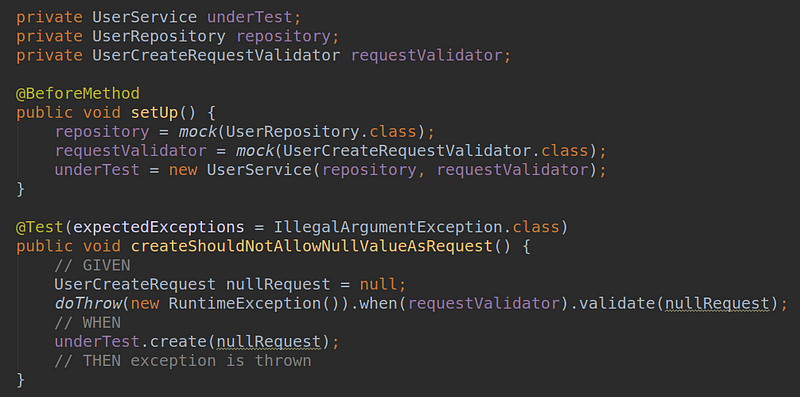
In this case, you configure it to throw an exception when it receives a null parameter. You even have to tell it what type of exception to throw.
What happens if someone sneaks in and modifies the validator code in the meantime? Do we trust that they changed the tests to match the new behavior? What if, going forward, it only logs a message every time instead of throwing an exception? Maybe the code has been updated in the corresponding XYValidatorTest, but here we’re testing a case that never happens. Naturally, a higher-level test would catch this error, but if we look at the test pyramid, we know we create fewer high-level tests, and perhaps this error will make it to the production environment. The bigger problem, though, is that it will be hard to find because we’ve ruined our best documentation, our test. From now on, it’s also lying, just like traditional documentation often does.
In summary:
- We can reduce the time spent creating mocks.
- We can separate our constructor from the test.
- We use the original implementations where possible.
These can help create an environment where safe refactoring is no longer just a dream.